برنامهنویسی تابعی با futures ها
همزمانی در سی++ - فصل ۴ - برنامهنویسی همروند تابعی

سلام. بعد از مدتهای مدید و طولانی دوباره میخوام شروع کنم به نوشتن پستهای فنّی و خلاصهنویسیهای خودم از کتاب C++ Concurrency in Action که هوف! بعد از مدت زیادی دوباره تونستم خودمو جمعوجور کنم و ادامهش رو بخونم. یه مدتی توی دفترچهم خلاصهنویسی کردم ولی به نظرم خلاصهنویسی توی وبلاگ خیلی بهتره!
درحال حاضر در اواخر فصل ۴ هستیم. توی این پست میخوام دربارهٔ اینکه چرا و چطور میشه با سی++ برنامهنویسیِ تابعی انجام داد و همروندش کرد.
مقدمه
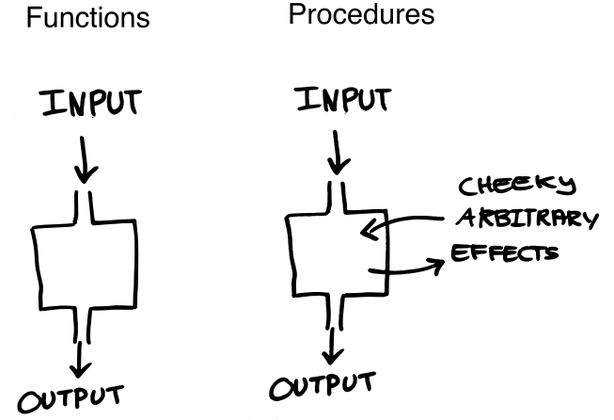
اول از همه باید بدونیم که «برنامهنویسی تابعی» چیست؟
به طور خلاصه برنامهنویسی تابعی به نوعی پارادایم برنامهنویسی گفته میشه که در اون، مقدار بازگشتی یک تابع منحصرا به پارامترهای اون وابستهست و هیچ وضعیتِخارجی(external state)ای روی خروجی تابع اثر نداره. درواقع این تعریفات، ریاضیاتی هستند که نتیجه این میشه که: اگر یک تابع رو دوبار با پارامترهای یکسان صدا بزنیم، خروجی تابع در هر دوبار(یا هرچندبار دیگه!) حتما باید یکسان باشه. همچنین، یک مفهوم دیگه به اسم «تابع خالص»(pure function) هم وجود داره که میگه: تابع نباید هیچ وضعیتِ خارجیای رو تغییر بده و دامنهٔ دسترسیش در حد scope خودش هست.
برای اطلاعات بیشتر میتونیم به صفحهٔ ویکیپدیا مراجعه کنیم و بیشتر بدونیم :)
اما چرا باید برنامهنویسی تابعی توی همروندی/همزمانی/... برای ما مهم باشه؟ برای پاسخ به این مسئله باید برگردیم به مشکلی که تا الآن داشتیم سعی میکردیم رفعش کنیم: اشتراکگذاری دادهها!
درواقع مشکل ما این بود که یکسری دادهٔ مشترک وجود داشت که خارج از تردها قرار داشتند و دسترسی(درواقع modify کردن) همزمان تردهای مختلف ممکن بود باعث اختلال بشه. اما وقتی هیچ modification همزمانی نداشته باشیم(همون تغییر ندادن external state!)، یعنی عملا چیزی به نام data race هم نخواهیم داشت.
زبانهایی مثل Haskell هستند که کلا functional هستند و همهٔ توابع به صورت پیشفرض در اونها pure هستند و از این زبانها زیاد برای برنامهنویسی همروند استفاده میشه.
توی سی++ هم میتونیم با استفاده از futures ها یک برنامهٔ تابعیِ همروند بنویسیم. به این شکل که future ها رو بین تردها پاس میدیم و به این ترتیب هیچ تغییری توی shared data بهوجود نمیاریم :)
پیادهسازی تابعی الگوریتم QuickSort
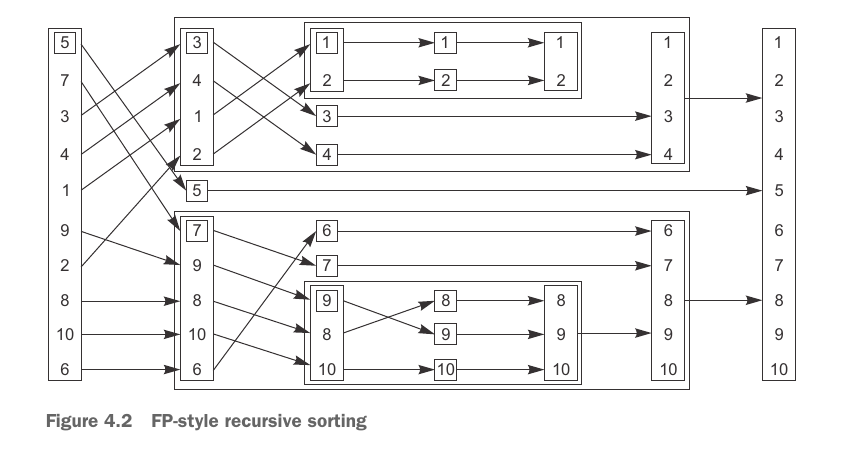
بهتره که خودتون جستجو کنید و دربارهٔ این الگوریتم بخونید ولی خب به شکل خلاصه بخوام بگم، در این الگوریتم ما یک عضو pivot رو انتخاب میکنیم و همهٔ اعضای دیگه رو بر اساس اون مرتب میکنیم.
عکس زیر به شکل خلاصه نشون میده که ما میخوایم چیکار کنیم:
وقتی pivot رو پیدا کردیم، اعداد کوچیکتر از pivot رو قبل از درایهٔ pivot و اعدادی که بزرگتر هستند رو بعد از pivot قرار میدیم. این عملیات رو انقدر تکرار میکنیم که دیگه عضوی برای مرتب کردن وجود نداشته باشه.
قبل از اینکه شروع کنیم به نوشتن نسخهٔ همروند، بهتره که اول نسخه ترتیبی رو داشته باشیم:
template<typename T>
std::list<T> sequential_quick_sort(std::list<T> input)
{
if(input.empty())
{
return input;
}
std::list<T> result;
result.splice(result.begin(), input, input.begin());
T const& pivot=*result.begin();
auto divide_point=std::partition(input.begin(), input.end(),
[&](T const& t)
{
return t < pivot;
});
std::list<T> lower_part;
lower_part.splice(lower_part.end(), input, input.begin(), divide_point);
auto new_lower(sequential_quick_sort(std::move(lower_part)));
auto new_higher(sequential_quick_sort(std::move(input)));
result.splice(result.end(), new_higher);
result.splice(result.begin(), new_lower);
return result;
}به نظرم کد خیلی واضح هست.(جملهٔ قبل رو زمانی نوشتم که تازه این قسمت کتاب رو خونده بودم. حدود ۲-۳ هفته پیش بود و خب الآن که کد رو نگاه میکنم میبینم خیلی هم واضح نیست(: ) این کد synchronous هست ولی تغییر دادنش به یک کد asynchronous کار سختی نیست. کافیه جاهایی که داریم تابع رو به صورت بازگشتی صدا میزنیم، بجای اینکه اونها رو در ترد فعلی صدا کنیم در یک ترد دیگه اجرا کنیم. نتیجه این میشه:
template<typename T>
std::list<T> parallel_quick_sort(std::list<T> input)
{
if(input.empty())
{
return input;
}
std::list<T> result;
result.splice(result.begin(), input, input.begin());
T const& pivot = *result.begin();
auto divide_point=std::partition(input.begin(), input.end(),
[&](T const& t)
{
return t < pivot;
});
std::list<T> lower_part;
lower_part.splice(lower_part.end(), input, input.begin(), divide_point);
std::future<std::list<T>> new_lower(
std::async(¶llel_quick_sort<T>, std::move(lower_part))
);
auto new_higher(parallel_quick_sort(std::move(input)));
result.splice(result.end(), new_higher);
result.splice(result.begin(), new_lower.get());
return result;
}البته اینجا برای اینکه از ترد فعلیمون هم استفاده کرده باشیم فقط قسمتی که lower_part رو مرتب میکنه در ترد جداگانه اجرا کردیم.
البته توی این کد از std::async استفاده شده. میتونیم مثلا با استفاده از std::packaged_task خودمون یک wrapper بنویسیم که برامون ترد ایجاد کنه و خب این باعث میشه که کنترل بیشتری روی فرآیند کار داشته باشیم و بعدا بتونیم پیادهسازیهای پیچیدهتری رو استفاده کنیم. نمونه کد:
template<typename F,typename A>
std::future<std::result_of<F(A&&)>::type> spawn_task(F&& f,A&& a)
{
typedef std::result_of<F(A&&)>::type result_type;
std::packaged_task<result_type(A&&)> task(std::move(f)));
std::future<result_type> res(task.get_future());
std::thread t(std::move(task),std::move(a));
t.detach();
return res;
}پایان
این بخش از کتاب هم تموم شد. قسمت بعدی دربارهٔ این صحبت کرده که چه راههایی برای رد و بدل کردن پیام بین تردها داریم. البته به نظرم باید یک پست دربارهٔ packaged_task و future و promise بنویسم چون همش بعضی استفادههاشون رو یادم میره...