یادگیری امروزم از معماری کامپیوتر(۴)
راجع به Pipeline Processing

بعد از چندروز دعوا با سگ وحشی افسردگی دوباره امروز تونستم یکم به مطالعهم برسم. درواقع علاوه بر یادگیری، اینکه بخوام سریعتر توی وبلاگم دربارش بنویسم هم بهم انگیزه داد
درواقع این پست حاصل یادگیری امروزم نیست و تقریبا یه هفتهست که روی این بخش گیر کردم. گاهی وقتا آدم سنگین تر از اونه که بخواد کاری انجام بده. اما بهرحال اینجاییم و داریم پیش میریم، هرچقدر هم که بخواد کًند باشه
پُست امروز دربارهی Pipeline Processing عه و احتمالا پست بعدی هم درباره همین مورد باشه.
پردازش خط لولهای(pipeline processing) یه تکنیکه که طی اون زیرعملها(sub operation) و یا بخش های مختلف از یک سیکل دستور، با همدیگه همپوشانی(overlap) پیدا میکنن.
این روش برای انجام کارها با تکرار زیاد بسیار مناسبه و نیازمند این هست که CPU چند فانکشنال یونیت مجزا داشته باشه که به صورت موازی کار انجام بدن.
دو بخش هست که پایپلاین داخلشون استفاده میشه یکیش arithmetic pipeline (عملیات های مختلف ریاضی رو به سگمنت های جدا تبدیل میکنه) و اون یکی هم instruction pipeline (بخش های مختلف مثل fetch و decode و execution رو به سگمنت های مختلف تبدیل میکنه)
معمولا بعد از هر سگمنت یک pipeline register وجود داره که نتیجهی حاصل شده از کار سگمنت قبل از خودش ذخیره میکنه و در اختیار سگمنت بعدی میذاره.(درواقع بین دو سگمنت A و B یک رجیستر وجود داره که به عنوان خروجی A و ورودی B میتونه محسوب بشه)
Arithmetic Pipeline
معمولا این پایپلاین برای انجام عملیات ها روی اعداد اعشاری و ضرب برای اعداد غیر اعشاری انجام میشه. توضیحاتش به نظرم بدیهی اومد بنابراین نمینویسمش.
Instruction Pipeline
همون طور که عمل پایپلاینینگ میتونه روی data stream ها انجام بشه، میتونه روی instruction stream هم انجام بشه. همونطور که میدونیم اجرای یه دستور از چند بخش تشکیل شده:
- fetch
- decode
- محاسبه effective address
- دریافت operand ها(fetch operand)
- اجرا(execute)
- write back
ما برای بررسی راحت تر چندتا از این بخش هارو باهم یکی میکنیم و فرض میکنیم مراحل اجرای یک دستور صرفا شامل مراحل زیر هست:
- fetch (FI)
- decode (DA)
- fetch operand (FO)
- execute (EX)
مثال ما ۴ استیج(سگمنت) هست اما توی کامپیوتر های دیگه تعداد استیج ها متفاوته(مثلا توی پنتیوم ۴ اینتل حدود ۳۰ تا استیج داریم).
توی جدول زیر میتونیم ببینیم که چطور بخش های مختلف باهم دیگه overlap پیدا میکنن. محور عمودی دستورات هستند و محور افقی کلاک ها هستن.
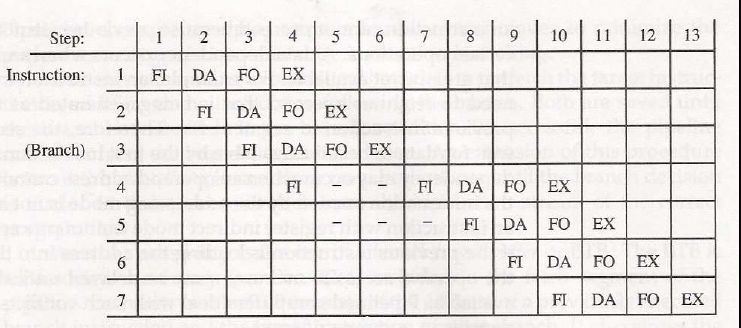
مشکلات instruction pipeline
- resource conflict ها
- Data dependency ها
- Branch difficulty ها
Resource Conflict
این مشکل زمانی رخ میده که دوتا سگمنت به صورت همزمان بخوان به مموری دسترسی داشته باشن. اینطور که کتاب گفته این مشکل معمولا با جدا کردن حافظهدیتا و اینستراکشن ها رفع میشه. اما خب این واسه کامپیوتر های خیلی قدیمیه، باید بگردم ببینم توی کامپیوتر های جدید این موضوع چطوریه.
Data Dependency
مشکل data dependency و address dependency که باعث کاهش پرفورمنس هم میشن، وقتی به وجود میان که یک سگمنت به یک داده و یا آدرسی نیاز داشته باشه که هنوز در دسترسش نیست. مثال: مثلا دستور A یک داده ای رو به عنوان خروجی تولید میکنه که این داده قراره به عنوان operand توی دستور B استفاده بشه. این دوتا دستور متوالی هستند، حالا قسمت Fetch operand(که میخواد اوپرند های دستور B رو لود کنه) تا زمانی که بخش Execute (که داره دستور A رو اجرا میکنه) تموم نشه نمیتونه داده های مورد نیاز خودش رو بدست بیاره. پس باید صبر کنه تا اجرای دستور قبلی به اتمام برسه تا کارش رو انجام بده. همین اتفاق برای آدرس ها هم میوفته. یعنی یک سگمنت به آدرسی نیاز داره که هنوز دستور قبلی تولیدش نکرده.
برای حل این مشکل معمولا سه تا راه وجود داره:
Hardware interlock
با اضافه کردن interlock، این مدار هروقت تشخیص بده که خروجی دستور فعلی قراره به عنوان ورودی دستور بعدی استفاده بشه، با استفاده از کلاک های اضافه تاخیر ایجاد میکنه تا اجرای دستور فعلی تموم بشه.
Operand forwarding
این راه حل اینطوریه که با استفاده از یه سری سخت افزارای خاص میان بین سگمنت های مختلف مسیر های جداگونه میسازن. یعنی چی؟ اینطوریه که به عنوان مثال اگر قرار باشه خروجی دستور A از ALU توی یک رجیستر خاص قرار بگیره، این مدار چک میکنه که آیا این رجیستر به عنوان ورودی دستور بعدی میخواد استفاده بشه؟ اگر جواب بله بود، به جای اینکه دیتا رو از ALU به رجیستر منتقل کنه و دستور بعدی با مراجعه به رجیستر اطلاعات موردنیاز خودش رو دریافت کنه، دیتا رو مستقیما به ورودی های ALU میفرسته تا برای دستور بعدی استفاده بشن.
Delayed load
توی این روش، حل این مشکل رو به عهدهی کامپایلری میذاریم که داره زبان سطح بالا رو به زبان سطح پایین تبدیل میکنه. درواقع کامپایلر وقتی data conflict رو میبینه، سعی میکنه با تغییر دادن ترتیب دستور ها(مثلا با اضافه کردن nop) به قدر کافی برای اجرا شدن دستور قبلی زمان ایجاد بکنه.
Branch difficulty
این مشکل درواقع یک چالش برای مدیریت کردن branch های رخ داده توی برنامهست. همونطور که میدونیم branch ها جریان عادی دستورات برنامه رو میشکنن. چالش اینه که چطور conditional branch و unconditional branch رو مدیریت کنیم که کمترین ضرر رو به پرفورمنس بزنیم.
Prefetch target instruction
این یکی از راه حل های موجود برای مدیریت کردن conditional branch هاست. نحوهی کارش اینطوریه که هردوحالت (اجرا شدن branch و اجرا نشدنش) رو درنظر میگیره. یعنی چی؟ یعنی شروع میکنه دستوراتی که در صورت وقوع branch قراره اجرا بشن و به صورت همزمان دستوراتی که در صورت انجام نشدن branch قراره اجرا بشن رو fetch میکنه. اگر شرط مربوط به branch درست بود، میره و دستورات branch رو(که قبلا fetch کرده) اجرا میکنه. در غیر این صورت دستورات مربوط به جریان عادی برنامه رو اجرا میکنه.
Branch Target Buffer(BTB)
BTB یه حافظه کوچیکه که توی استیج fetch قرار میگیره.کارش اینه که آدرس چند branch اجرا شدهی اخیر + آدرس target اونها + چندتا از instruction های بعد از target رو داخل خودش ذخیره میکنه. وقتی دستور توی پایپلاین رمزگشایی دیکد میشه، توی BTB میگرده که آیا آدرس این دستور(که یه branch هست) توی BTB وجود داره یا نه. اگه وجود داشته باشه، اون دستور و متعلقاتش(مثل آدرس تارگت و چندتا دستور اولِ اون branch) مستقیما در دسترس هستند و دستورات از مسیر جدید به سرعت fetch میشن. اگه آدرس جستجو شده توی BTB وجود نداشته باشه، این دستور به علاوهی متعلقاتش توی BTB ذخیره میشن و پایپلاین خالی میشه تا مسیر جدید دستور ها توی پایپلاین قرار بگیره.
Loop buffer
یکی از انواع BTB عه که شامل یه رجیستر فایل بسیار سریعه و توسط بخش fetch مدیریت میشه. وقتی مشخص میشه قراره یه حلقه اجرا بشه، کل محتویات اون حلقه داخل این بافر ذخیره میشه و بنابراین برای اجرای دستورات داخل حلقه نیازی به رجوع به حافظه نیست.
دستورات داخل حلقه تا پایان اجرای حلقه داخل این بافر میمونن.
Branch Prediction
یکی از بحث های خفن معماری کامپیوتره که خیلی دربارهش بحث میشه. توی این کتاب تا اینجا توضیح مختصری داده اما با جستجویی که خودم کردم مثل اینکه موضوع خیلی بحث برانگیز و جالبیه.
branch prediction درواقع فرآیندیه که طی اون پایپلاین سعی میکنه قبل از اجرا شدن یه conditional branch حدس بزنه که آیا شرط (condition) صدق خواهد کرد یا نه. در صورتی که پیشبینی کنه این شرط درست خواهد شد، شروع میکنه دستوراتِ داخل branch رو fetch میکنه. اگر پیشبینی درست باشه، دیگه وقفه ای در کار پایپلاین رخ نمیده.
در آخر
برای اینکه این پست طولانی نشه، ادامهی مطالب این پست رو توی پست بعدی مینویسم که اون هم دربارهی پردازش موازیه