memory model در سی++
این فصل درباره مدل حافظه یا Memory Model در سی++ هست. البته این فصل که نه، منظورم این زیرفصل هست. کلیت فصل درباره مدل حافظه و عملیاتهای اتمیک است. از مدل حافظه شروع میکنیم


سلام. امروز پنجم فروردین(ادامهٔ این پست در تاریخ ۱۴ اردیبهشت نوشته شد.....!) سال ۱۴۰۱ هست. اولین پست من در قرن و سال جدید رو دارید مشاهده میکنید. نمیخوام مثل تقریبا همهٔ پستهای دیگهم غر بزنم. پس سعی میکنم برم سر اصل مطلب. ولی کلی بخوام بگم، چندین ماهه که میخوام بنویسم و نمینویسم. پوف. بگذریم...
فصل پنجم کتاب C++ Concurrency In Action شروع شده(واقعا دیگه دارم احساس حماقت میکنم با این سرعت مطالعهم) و این فصل درباره مدل حافظه یا Memory Model در سی++ هست. البته این فصل که نه، منظورم این زیرفصل هست. کلیت فصل درباره مدل حافظه و عملیاتهای اتمیک است. از مدل حافظه شروع میکنیم:
یک اصل در مدل حافظهای سی++ هست: «همهٔ دادهها یک شئ هستند». نباید این جمله رو با جملات مشابهای که توی زبانهای برنامهنویسی دیگه مثل پایتون و ... میبینیم اشتباه بگیریم. کمیته استاندارد سی++ هر شئ رو یک Region of Storage تعریف کرده. البته این اشیاء یکسری Property مثل lifetime و type هم میتونن داشته باشن. بنابراین همهچیز یک شئ توی حافظهست. چه int باشه چه یه کلاسی که خودمون تعریفش کردیم. همچنین یکسری اشیاء، زیرشئ هم دارن(مثل آرایهها و آبجکتهایی از کلاسهای دارای non-static data member و ...).
این اشیاءای که گفتیم، میتونن در یک یا چند memory location جا بگیرن.
حالا کتاب یک struct رو نوشته و اون رو از نمای حافظه نشون داده. تصویر جالبیه:
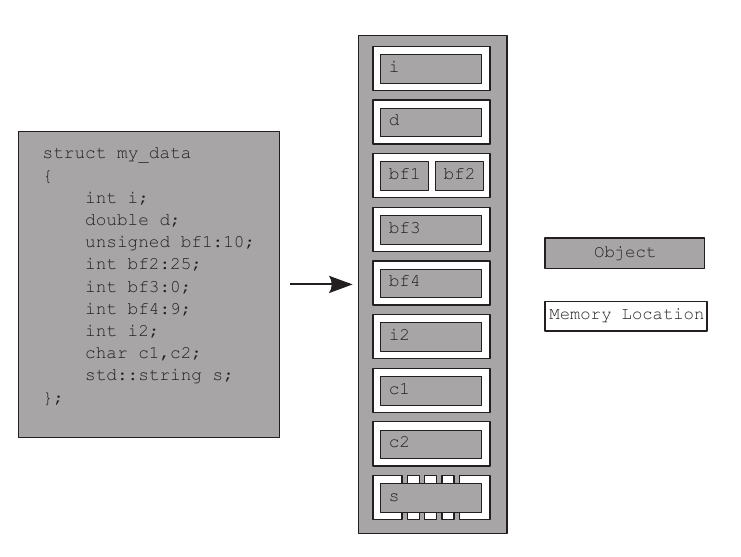
نکاتی که باید بهش توجه بشه اینه که:
bf1وbf2که adjacent bitfield هستند، یک memory location رو با یکدیگه شریک شدهند.bf3چون اندازهش صفر هست باعث شده کهbf4یک memory location مخصوص به خودش رو داشته باشه(نمیدونم دقیقا چرا!)- شئ
sکه یکstd::stringهست، خودش دارای زیرشئ یا sub-object است - هر متغییر یک شئ در حافظه محسوب میشه.
- هر شئ در حافظه حداقل یک memory location جا میگیرد.
- متغییرهای از نوع primitive مثل int, float, ... فقط یک memory location جا میگیرند.
حالا با همهٔ این چیزهایی که گفته شد میتونیم مفهوم Race Condition رو به همراه مفهوم Memory Location ها استفاده کنیم:
اگر دوتا ترد به شکل همزمان به دوتا memory location مختلف دسترسی پیدا بکنن مشکلی نیست. اما اگر هر دو ترد قرار باشه که به یک مموری لوکیشن یکسان دسترسی پیدا کنن و یک یا هردوشون بخوان عملیات نوشتن رو انجام بدن، اونوقت Race Condition داریم.
راه جلوگیری از Race condition این هست که دسترسیها دارای یک نوع ترتیب(حالا از هر نوعش) باشند. استفاده از Mutex ها یکی از این ترتیبهای اجباریای است که ما به برنامه اضافه میکنیم. یک راه دیگه هم استفاده کردن از عملیاتهای atomic برای sycnronization هست.
Modification Orders: ترتیب عملیاتها
هر شئ حافظهای در سی++ یک «ترتیب تغییر» داره که از تمام «عملیاتهای نوشتن» روی اون شئ تشکیل شده. تردها باید روی این ترتیب به توافق برسن. بخاطر همین تفاوت در Modification Orderها است که race condition بهوجود میاد. وقتی از عملیاتهای اتمیک استفاده میکنیم، کامپایلر وظیفه داره که این syncronization و ترتیب تغییرات رو برای شئ مورد نظر به درستی مدیریت کنه.
انواع اتمیکها و عملیات روی آنها در سی++
یک عملیات اتمیک به عملیاتی میگن که قابل تقسیم شدن نباشه. یعنی این عملیات فقط یک شروع داره و یک انتها. یعنی اینکه تردها هیچوقت نمیتونن وضعیت این عملیات رو در حین اجرا ببینن. همیشه وضعیت رو یا قبل از شروع فرآیند میبینن یا بعد از اتمامش. بنابراین بهعنوان مثال، اگر یک عملیات اتمیک load رو روی یک متغییر اتمیکی که مابقی عملیاتها(شامل نوشتن) هم روی این متغییر، اتمیک هستند انجام بدیم، مقداری که توسط load برگردونده میشه یا مقدار اولیهٔ اون متغییر هست یا مقداری که بعد از modification روی اون متغییر ایجاد شده.
در سی++ برای انجام دادن عملیاتهای اتمیک، به متغییرهای اتمیک نیاز داریم.
اتمیکهای استاندارد سی++
برای استفاده از Type اتمیک، باید به کتابخانه atomic در سی++ رجوع کنیم و اشیاء رو از کلاس std::atomic بسازیم. به شکل کلی، میشه گفت که تمام عملیاتها روی آبجکتهای این کلاس از نوع اتمیک هستند. ولی یکسری جزئیات هم وجود داره:
اینکه واقعا عملیاتها روی یک شئ از نوع اتمیک باشه یا نه، بستگی به پیادهسازی کلاس std::atomic برای نوع مورد نظر ما داره. برای اینکه بفهمیم شئ مورد نظر ما اتمیک هست یا نه، باید از عضو تابعی (member function)ای به نام ()is_lock_free استفاده کنیم. این یعنی چی؟ یعنی اینکه ممکنه از یک نوع مثل std::atomic<uintmax_t> بخوایم استفاده کنیم. با استفاده از تابع ذکر شده میتونیم بفهمیم که در پیادهسازیِ زیرین، آیا عملیاتها روی این نوع از دادهها با استفاده از دستورات atomic انجام میشن یا اینکه صرفا یک internal lock وجود داره و عملا اون زیر داره از mutex استفاده میشه؟ چیزی که ما در استفاده از متغییرهای اتمیک دنبالش هستیم اینه که از شرّ lock و mutex ها خلاص بشیم! پس استفاده از این نوع اتمیکها یکجورایی نقض غرض هست.
در نهایت انتظار میره که روی سکوها و پلتفرمهای مرسوم، پیادهسازی اتمیک از همهٔ نوع دادههای built-in از نوع lock-free باشن.
متغییرهای اتمیک دارای Copy Constructor و Copy Assignment Operator نیستند. ولی از implicit conversion و assignment-from از طریق تابعهای store() ، exchange() ، compare_exchange_weak() و compare_exchange_strong() پشتیبانی میکنن.
میشه از std::atomic برای دادههای user-defined هم استفاده کرد و specialization رو انجام داد. منتها اونوقت دیگه صرفا محدود به عملیاتهایی هستیم که چند خط قبل اسم تابعشون رو گفتم.
توابعی که جهت عملیات روی متغییرهای اتمیک نام بردم، یک آرگومان اضافه هم برای مشخص کردن memory order دارند. این آرگومان، یک enumeration از std::memory_order هست که ۶ نوع مختلف داره و بسته به نوع عملیات میشه اونها رو استفاده کرد:
memory orderهای مورد نظر عبارتاند از:
std::memory_order_relaxedstd::memory_order_acquirestd::memory_order_consumestd::memory_order_acq_relstd::memory_order_releasestd::memory_order_seq_cst
مقدار انتخابی پیشفرض برای عملیاتها، std::memory_order_seq_cst هست که قویترین memory orderها محسوب میشه. در ادامه همین فصل راجع به جزئیات این memory orderها بیشتر بحث میشه ولی فعلا به همین مورد که کجاها میشه ازشون استفاده کرد اکتفا میکنیم:
- برای عملیاتهای Store، میشه از memory_order_relaxed، memory_order_released و memory_order_seq_cst استفاده کرد.
- برای عملیاتهای Load، میشه از memory_order_relaxed, memory_order_consume,memory_order_acquire یا memory_order_seq_cst استفاده کرد.
- برای عملیاتهای Read-Modify-Write میشه از همهٔ شش memory order موجود استفاده کرد.
عملیات روی std::atomic_flag
سادهترین نوع متغییرهای اتمیک، std::atomic_flag است. تعداد توابع خیلی خیلی محدودی داره(فقط یک نابودگر، یک تابع clear و یک تابع پرسش و تخصیص داره). میشه به عنوان یک Boolean نمایشش داد. اساساً از این نوع متغییر بیشتر به عنوان یک building block استفاده میشه و احتمال خیلی کمی وجود داره که به شکل مستقیم اون رو ببینیم. اما چیز جالبیه(کلا از نظر من این atomicها چیز جالبی هستند). یک نکته در استفاده از این type هست و اونم در زمان initialize کردنشه. حتما و حتما باید در زمان initialize، مقدار اولیه رو برابر با ATOMIC_FLAG_INIT قرار بدیم! یعنی اینجوری:
std::atomic_flag f = ATOMIC_FLAG_INIT;این نوع اتمیک، تنها اتمیکی هست که این نوع رفتارهای خاص رو از برنامهنویس انتظار داره و همچنین تنها اتمیکی هست که تضمین lock-free بودن رو به ما میده. کتاب با استفاده از این نوع اتمیک، یک Spin-Lock پیادهسازی کرده که من هرچقدر خوندمش نفهمیدم این چطور کار میکنه. کدش رو اینجا نمیارم چون توی قسمتهای بعد قراره دوباره به کدش بربخوریم و اونجا ظاهرا کتاب قراره که توضیح بده چرا اون کد داره کار میکنه.
عملیات روی std::atomic<bool<
این نوع از دادههای اتمیک عملا همون atomic_flag هست ولی با امکانات بیشتر. مثل مابقی متغییرهای اتمیک، این type هم copy-constructible و copy-assignable نیست. ولی قابلیت Assign کردن یک مقدار غیر اتمیک به یک متغییر اتمیک وجود داره و همچنین میشه یک مقدار true یا false به عنوان مقدار اولیه بهش داد. مثل این:
std::atomic<bool> b(true);
b = false; // Assign non-atomic to atomicبرای ذخیره کردن دادهٔ جدید، از تابع store() استفاده میکنیم و بجای تابع test_and_set() توی atomic_flag اینجا تابع exchange() رو داریم که یک مقدار جدید میگیره، مقدار قدیمی رو برمیگردونه و سپس مقدار جدید رو جایگزین مقدار قدیمی میکنه. به این عملیات میگن عملیات Read-Modify-Write. برای خوندن داده(عملیات Load) هم از تابع load() استفاده میشه و با implicit conversion، دادهٔ بازگشتی به شکل bool برگشت داده میشه.
std::atomic<bool> b;
bool x = b.load(std::memory_order_acquire);
b.store(true);
x = b.exchange(false, std::memory_order_acq_rel);ذخیره کردن یا نکردن یک مقدار جدید بر اساس مقدار قبلی
اسم این عملیات، compare-exchange هست. این عملیات یکی از سنگبناهای برنامهنویسی با دادههای اتمیک هست و خیلی اهمیت بالایی داره. کارش این هست که یک مقدار مورد انتظار و یک مقدار جدید رو میگیره، مقدار فعلی خودش رو با مقدار مورد انتظار مقایسه میکنه و اگر اونها یکی بودند، مقدار جدید رو با مقدار فعلی خودش عوض میکنه. اگر مقادیر یکی نبودند، مقدار مورد انتظار رو برابر با مقدار فعلی قرار میده(بنابراین داره یک ارجاع از متغییر مربوط به مقدار مورد انتظار دریافت میکنه که بتونه تغییرش بده). در کتابخانه استاندارد سی++ برای این عملیات دو تابع به نامهای compare_exchange_weak() و compare_exchange_strong() داریم. مقدار بازگشتی این توابع در صورتی که موفق به تعویض مقادیر بشن، true و در غیر این صورت false هست.
حالا فرق این دوتا چی هست؟ تابع compare_exchange_weak() ممکنه حتی زمانی که دادهٔ مورد انتظار با دادهٔ فعلیش مطابقت داره، باز هم fail بشه و مقادیر رو عوض نکنه. طبق گفتهٔ کتاب، این حالت بیشتر در ماشینهایی پیش میاد که instruction خاص مربوط به عملیات compare-exchange رو ندارند و بنابراین پردازنده ممکنه که ترد رو وسط انجام عملیات از این پردازه بگیره و به یه پردازه دیگه اختصاص بده. به این حالت از fail شدن میگن spurious failure.
برای همین معمولا برای استفاده از این تابع باید از حلقه استفاده کنیم:
bool expected = false;
extern atomic<bool> b; // set somewhere else
while (!b.compare_exchange_weak(expected, true) && !expected);توی حلقه ما مقدار expected رو هم چک میکنیم که مطمئن بشیم حلقه رو تنها زمانی تکرار بکنیم که spurious failure اتفاق افتاده.
تابع compare_exchange_strong() تنها زمانی مقدار false برمیگردونه که مقدار مورد انتظار و مقدار فعلی، باهم متفاوت باشن.
یه چیز جالب دیگهٔ این دو تابع این هست که دو memory order رو به عنوان آرگومان خودشون قبول میکنن: یکی برای زمان success و یکی هم برای زمان fail.
عملیات روی std::atomic<T*>: محاسبات اشارهگرها
متغییر اتمیکی که داده از نوع اشارهگر رو ذخیره بکنه، خیلی شبیه همون std::atomic<bool>ای هست که بالاتر دیدیم و مشخصا همهٔ قابلیتهای اون رو داره به علاوه اینکه یکسری قابلیتهای اضافه که مربوط به محاسبات اشارهگرها هست رو هم داره و تنها فرقش این هست که بجای bool، یک داده از نوع اشارهگر رو در خودش ذخیره میکنه.
عملیاتهای اضافهای که این نوع از اتمیک داره، توابع fetch_add() و fetch_sub() هستند که یک عددی رو به/از آدرس اشارهگر اضافه/کم میکنند. همچنین عملگر(اوپراتور)های مختلفی از جمله -=،+= و ++،-- هم به صورت پیشوند هم پسوند رو پشتیبانی میکنه. اگر فرض کنیم x یک std::atomic<int*> هست و به اولین خانهٔ یک آرایه اشاره میکنه، x += 1 باعث میشه که x به دومین خانه از اون آرایه اشاره بکنه. اینجاست که تفاوت عملگرها با function memberهای fetch_add() و fetch_sub() مشخص میشه. چون مقداری که این توابع برمیگردونن، مقدار فعلی اشارهگر هست نه آدرس جدیدی که با کم/زیاد کردن اشارهگر بدست اومده(یعنی تغییرات رو انجام میدن ولی مقداری که برمیگردونن، مقدار قبل از اعمال تغییرات هست). به این عملیاتها میگن exchange-and-add. کد زیر خیلی خوب همهٔ اینها رو توضیح میده:
class Foo{};
Foo some_array[5];
std::atomic<Foo*> p(some_array);
Foo* x = p.fetch_add(2);
assert(x == some_array);
assert(p.load() == &some_array[2]);
x = (p -= 1); // checkpoint 1
assert(x == &some_array[1]);
assert(p.load() == &some_array[1]);به نظرم نکته قابل توجه این هست که حواسمون باشه متغییرهای اتمیک توی Assign کردن مثل بقیهٔ دادهها نیستند که یک ارجاع برگردونن. اونها یک value از نوع دادهای که درون اتمیک وجود داره برمیگردونن(checkpoint 1).
عملیات روی متغییرهای اتمیک عددی
این نوع دادهها چیز خاصی نسبت به مابقی اتمیکهایی که تا الآن گفتیم ندارند. فقط یکسری عملگر اضافه مثل and و or و xor بیتی بهعلاوه سهتا تابع متناظرشون به شکل fetch_*() رو به همراه خودشون دارن. تقریبا همهٔ کارهای لازم رو انجام میدن و فقط عملیاتهای ضرب و تقسیم و شیفت رو به شکل مستقیم پشتیبانی نمیکنن که اونم به دلیل اینکه این نوع متغییرها معمولا به عنوان شمارنده و امثالهم بکار میرن، چیز خیلی مهمی نیست(هرچند، از راههای غیرمستقیم مثل توابع exchange همچنان میشه برای این عملیاتها استفاده کرد).
The std::atomic<> primary class template
وجود Primary Templateها باعث میشن که بتونیم علاوه بر Typeهای built-in خود سی++، انواع دادهای خودمون (User Defined Type) رو هم به همراه std::atomic استفاده بکنیم.
اتمیکهایی که با استفاده از دادههای تعریف شده توسط کاربر میسازیم رابطی مشابه رابط std::atomic<bool> دارن. البته که نمیشه همینجوری هرنوع دادهای که دلمون میخواد رو توی شکم std::atomic بذاریم بلکه این نوع دادهها میبایست یکسری شرایط رو داشته باشن:
دادهها باید trivial copy-assignment operator داشته باشن. یعنی اینکه:
- نه خودش نه والدش تابع Virtual نداشته باشن و همچنین والدش یک virtual class نباشه.
- اوپراتور Copy-Assignment توس خود کامپایلر تولید شده باشه
- همهٔ non-Static Data-Memberهای کلاس و والدش باید شرایط بالا رو داشته باشن.
شرایط بالا باعث میشه که کامپایلر بتونه به راحتی از توابعی شبیه memcpy() استفاده بکنه.
برای توابع Compare-Exchange، کامپایلر از توابعی مانند memcmp() استفاده میکنه. بنابراین اوپراتورهای مقایسهای که توسط کاربر تعریف میشن به کار نمیان. حتی ممکنه Padding Bitها باعث بشن که مقایسه به درستی انجام نشه و در نهایت تابع Compare-Exchange نتونه کارش رو انجام بده.
اصلیترین دلیل اینکه اینکه چرا این محدودیتها هستن، بخاطر guidlineای هست که در فصل ۳ خوندیم:
«نباید دادهای که با استفاده از Lock محافظت شده رو به شکل ارجاع(یا اشارهگر) به یک تابع User-Defined بدیم»
از اونجایی که در حالت کلی کامپایلر برای user defined typeها از lock استفاده میکنه، اگر کامپایلر بخواد از توابع تخصیص یا مقایسهای که توسط کاربر نوشته شده استفاده کنه باید یک ارجاع یا اشارهگر به دادهای که ازش محافظت شده رو به تابع ذکر شده بده و این خلاف guidline هست.
در نهایت هرچه که ما بتونیم نوع دادهٔ خودمون رو شبیه به raw byte بکنیم، احتمال اینکه کامپایلر بتونه برای ما یک پیادهسازی lock-free و با استفاده از instruction های atomic ایجاد بکنه بیشتر هست.
به شکل معمول اگه اندازهٔ UDT ما به اندازهٔ یک int یا void* باشه، اکثر پلتفرمها میتونن از دستورات اتمیک(atomic instructions) برامون استفاده کنن. البته، یکسری از پلتفرمهایی هستند که از دستورات double-word-compare-and-swap(DWCAS) پشتیبانی میکنن که اونها میتونن دستورات اتمیک رو روی دادههایی با اندازهٔ ۲ برابر int اجرا بکنن.
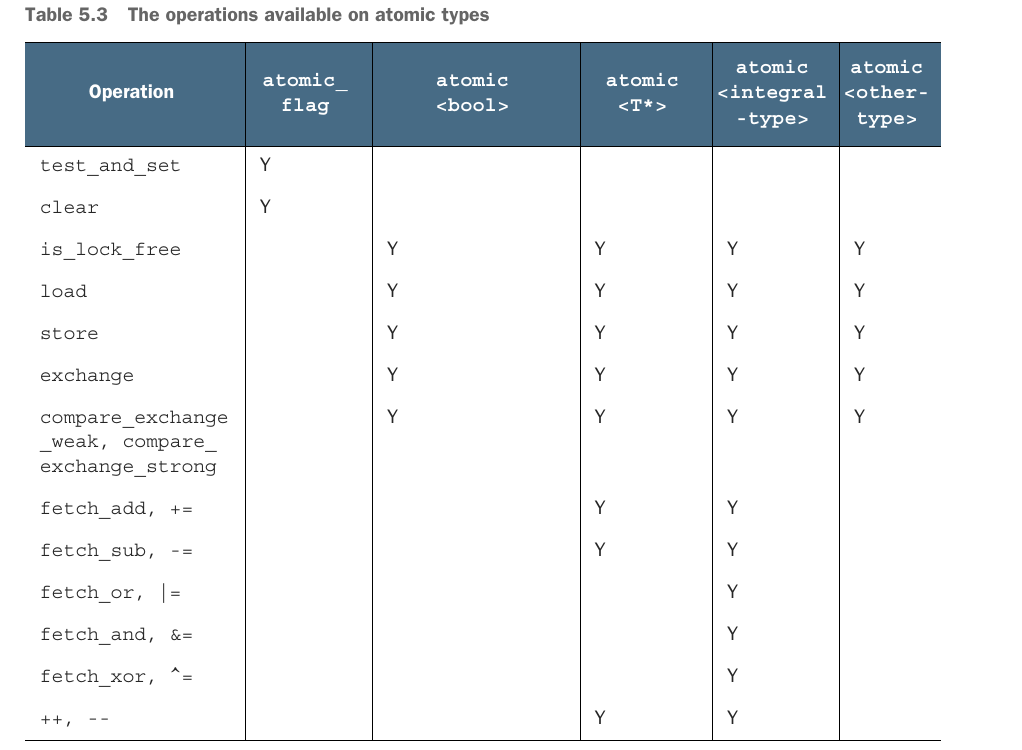
تصویر زیر بهطور خلاصه نشون میده که انواع مختلف اتمیک چه عملیاتهایی رو پشتیبانی میکنن:
عملیاتهای اتمیک با استفاده از Free Functionها
عملیاتهایی که تا به الآن دیدیم، اکثرا توابعی بودند که به عنوان متود(یا Member-Function) اشیاء اتمیک ازشون استفاده میکردیم. کمیتهٔ استاندارد سی++ این توابع رو به شکل Free-Function هم تعریف کرده. فرقی با توابعی که از طریق خودِ شئ استفاده میکنیم ندارن(جز اینکه اول اسم هر تابع یک _atomic اضافه شده) و فقط رابطشون به شکل زبان C است. مثال:
بجای اینکه اینطور بنویسیم:
std::atomic<int> a;
a.store(1);اگر بخوایم از free functionها استفاده کنیم، اینطوری میشه:
std::atomic<int> a;
std::atomic_store(&a, 1);همونطور که مشخصه، باید یک اشارهگر از شئ اتمیک رو به تابع مورد نظر بدیم. و اگر میخوایم memory order هم مشخص بکنیم، کافیه که آخر تابع یک explicit بذاریم. مثلا اینطوری: std::atomic_store_explicit()
همچنین Concurrency TS یک نوع جدید به اسم std::experimental::atomic_shared_ptr<T> ارائه داده که احتمالا همونطور که مشخصه، یک shared_pointer است که عملیاتهای روش اتمیک(و با احتمال بالا، lock-free) هستند. توابعی که پشتیبانی میکنه هم مشابه توابع پشتیبانی شوندهٔ User Defined Typeها است.
پایان
همونطور که توی این پست توضیح داده شد، اتمیکها خیلی بیشتر از صرفا یک ابزار جلوگیری از data-race هستن. اونا میتونن ترتیب عملیاتها بین تردهای مختلف رو کنترل کنن و این سنگبنای mutex و future و ... است. توی پست بعدی به جزئیات مدل حافظهای و اینکه واقعا چطور میشه از اتمیکها توی کار واقعی استفاده کرد میپردازیم.
عزت زیاد.