ترتیبهای حافظه در عملیاتهای اتمیک سی++
توی این پست درباره اینکه چطور میتونیم ترتیبهای مدنظر خودمون رو برای عملیاتها اعمال کنیم صحبت میکنیم و تفاوت ترتیبهای مختلف حافظهای رو توی کدهای مختلف بررسی میکنیم.

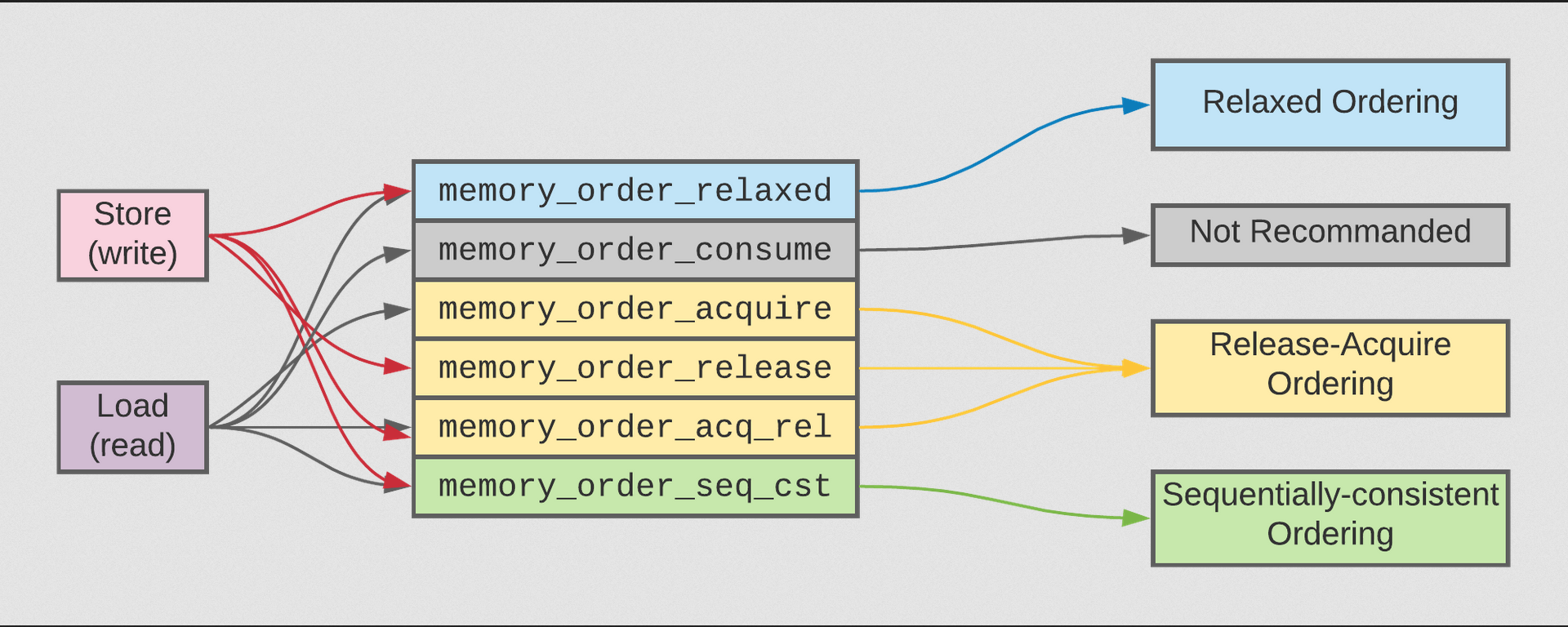
در سی++، ۶ گزینه برای ترتیب عملیاتها وجود داره که میشه برای عملیاتهای اتمیک ازشون استفاده کرد و اون ۶ گزینه اینها هستند:
- memory_order_relaxed
- memory_order_consume
- memory_order_acquire
- memory_order_release
- memory_order_acq_rel
- memory_order_seq_cst
اگر برای عملیاتهای اتمیکمون از هیچکدوم این موارد استفاده نکنیم، گزینهٔ memory_order_seq_cst به صورت پیشفرض انتخاب خواهد شد. درسته که ۶ گزینه قابل استفاده داریم اما این ۶ گزینه درواقع در ۳ مدل حافظهای خلاصه میشن:
- مدل Sequentially Consistent Ordering (گزینه memory_order_seq_cst)
- مدل Acuire-Release (گزینههای memory_order_consume, memory_order_acquire, memory_order_release و memory_order_acq-rel)
- مدل Relaxed (گزینهٔ memory_order_relaxd)
این مدلهای مختلف ممکنه هزینههای مختلفی روی پردازندههای مختلف داشته باشند. به عنوان مثال، روی معماریهای پردازندههایی که کنترل زیادی روی قابل مشاهده بودن instructionهای یک پردازنده توسط مابقی پردازندهها وجود داره، ممکنه مدل Sequentially Consistent به نسبت مدل acquire-release و relaxed، دستورات بیشتری رو جهت حفظ همگام بودن اجرا بکنه و مدل acquire-release هم سربار بیشتری نسبت به relaxed داشته باشه.
از طرف دیگه، مثلا توی معماری X86 یا X86-64 عملیاتهای acquire-release نیاز به انجام دستورات(instruction) اضافه ندارند و حتی در Sequentially Consistent برای عملیاتهای load نیازی به دستورات اضافه نیست و برای عملیاتهای store کمی سربار وجود داره.
حالا هرکدوم از این موارد گفته شده رو بررسی میکنیم:
Sequentially Consistent Ordering
این مدل، به گفتهٔ کتاب سادهترین و شهودیترین مدلی هست که وجود داره و فهمش راحتتره. البته نمیدونم چرا فهم این مدل برای من سختتر از مابقی مدلها بود!
در این مدل، اگر همهٔ عملیاتهایی که روی اتمیک مورد نظرمون انجام میدیم از نوع seq cst باشه، رفتار برنامهٔ چندنخی(multi-threaded) ما طوری میشه که انگار این عملیاتهای ذکر شده دارن با یک ترتیب خاصی و توی یک ترد اجرا میشن.
بنابراین همهٔ تردها باید یک ترتیب یکسانی از عملیاتها رو ببینند و این یعنی عملیاتها نمیتونن re-order بشن. به عبارت دیگه، اگر دو عملیات در یک ترد پشت سر هم انجام بشن، این ترتیب باید در همهٔ تردهای دیگه قابل مشاهده و یکسان باشه.
اگر بخوایم از نگاه همگامسازی (synchronization) نگاه بکنیم، یک عملیات store با مدل sequentially consistent، یک رابطه synchronized-with با عملیات load(طبیعتا روی همون متغییر که store کرده) مدل sequentially consistent برقرار میکنه. بدین صورت ما یک ترتیب برای اجرا شدن عملیاتها(operations) داریم. همچنین، هر عملیات sequential consistentای که بعد از اون load قرار گرفتن هم نمیتونن قبل از store اجرا بشن و حتما باید بعد از store متناظر با اون load اجرا بشن.
سادهفهم بودن این مدل و این یکسان بودن ترتیب عملیاتها بین همهٔ پردازندهها، بدون هزینه نیست. مثلا با تعداد پردازنده زیاد در حالی که معماری سیستم weakly-ordered هست، استفاده از این مدل و یکسان نگهداشتن ترتیب عملیاتها بین پردازندهها میتونه synchronization operationهای سنگینی رو به سیستم تحمیل بکنه. البته معماری x86 این سربار اضافه رو نداره و با هزینه نسبتا پایینی میتونه عملیاتهای sequential consistent رو انجام بده.
کد زیر یک مثال برای استفاده از این مدل هست:
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x()
{
x.store(true,std::memory_order_seq_cst); // Point 1
}
void write_y()
{
y.store(true,std::memory_order_seq_cst); // Point 2
}
void read_x_then_y()
{
while(!x.load(std::memory_order_seq_cst));
if(y.load(std::memory_order_seq_cst)) // Point 3
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_seq_cst));
if(x.load(std::memory_order_seq_cst)) // Point 4
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0); // Point 5
}در مثال بالا هیچگاه assert در نقطهٔ ۵، trigger نخواهد شد. باهمدیگه سناریوهای اجرای این برنامه رو بررسی میکنیم.
فرض کنیم x زودتر از y برابر با true قرار میگیرد و زمان رسیدن برنامه به نقطهٔ ۳ همچنان y برابر با true نشده باشد. بنابراین در تابع read_x_then_y مقدار z افزایش پیدا نمیکند. حال از آنجایی که بین store و load متغییر x رابطه happens befor و synchronizes with دارن و همونطور که بالاتر گفتیم عملیاتهایی که بعد از load میان هم همچنان بعد از store اجرا میشن، میشه نتیجه گرفت که عملیات store روی x قبل از store روی y انجام شده. بعد از اینکه عملیات store روی y انجام میشه، تابع read_y_then_x به نقطه شماره ۴ میرسه. متغییر x که قبلا true شده بود پس مقدار z برابر با ۱ میشه.
توی این سناریو ای که توضیح داده شد، عملیات load y ای که مقدار false رو برمیگردوند به صورت ضمنی با عملیات store y که مقدار true رو در y ذخیره میکنه synchronize میشه(یعنی حتما load y موردد نظر قبل از store y اتفاق افتاده).
حالا همین سناریو رو میشه برعکس کرد. یعنی y زودتر از x برابر با true بشه. دقیقا همین اتفاقهایی که توضیح دادم میافتن و فقط جای y و x عوض میشه. توی عکس پایین رابطه happens-befor برای مثال بالا و برای حالتی که x زودتر از y مقداردهی بشه به تصویر کشیده شده. اون خطچینها هم همون synchronization ضمنیای هست که یه پاراگراف قبل توضیح دادم.
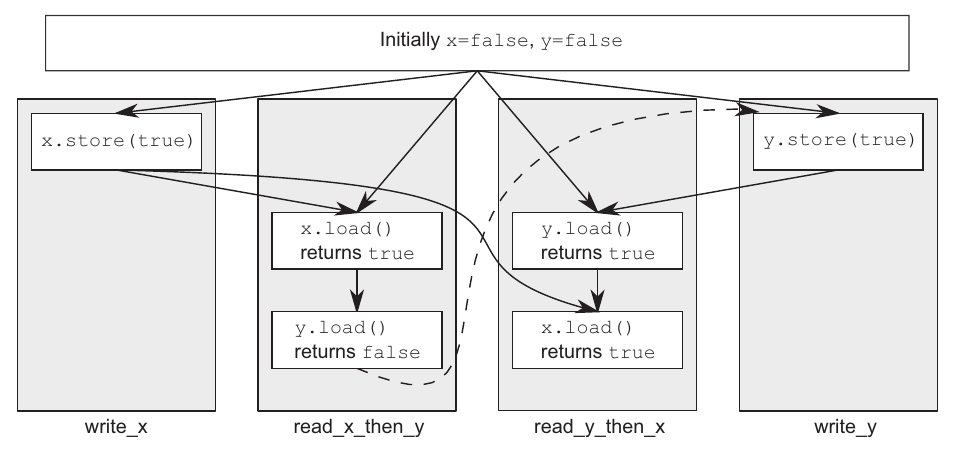
مدل sequentially consistent ساده و سرراستترین مدل برای استفاده هست اما پرهزینهترین مدل نیز هست چون باید یک همگامسازی جهانی (global synchronization) رو بین تردها ایجاد بکنه و این مورد توی سیستمهای چند پردازندهای ممکنه خیلی هزینهبر باشه.
Non-Sequentially Consistent Ordering
وقتی از فضای sequential consistency خارج میشیم، اوضاع کاملا فرق میکنه. دیگه اینجا به معنای واقعی کلمه هیچ ترتیبی از رویدادها وجود نداره. اینجا جاییه که باید همهٔ افکار و مدل فکری گذشته رو دور بریزیم. گذشت اون دورانی که عملیاتها ترتیب داشتند. دورانی در اون فکر میکردیم عملیاتهای تردهای مختلف با ظرافت و سرعت بالایی پشت سر همدیگه اجرا میشن. توی این دوران جدید، باید روی این حساب کنیم که عملیاتها به معنای واقعی کلمه به طور همزمان اتفاق بیوفتن و هیچ توافقی روی ترتیب رویدادها هم ندارن.
بنابراین ممکنه حتی تردها درحال اجرای یک کد یکسان باشند اما به دلیل اینکه ممکنه کَش و بافرهای داخلی پردازنده برای اون حافظه دارای مقادیر مختلف باشن، میتونن روی ترتیب رویدادها توافقی نداشته باشن.
تردها نیازی ندارند که روی ترتیب رویدادها توافق کنند
تردها فقط برای modification order روی هر متغییر توافق میکنن. بنابراین عملیاتها روی متغییرهای مختلف و توی تردهای مختلف ممکنه ترتیب متفاوتی داشته باشند!
برای اینکه این هرج و مرج رو خوب بفهمیم سراغ بزرگترشون که به صراطهای کمی مستقیم هست میریم: memory_order_relaxed
Relaxed ordering
عملیاتهایی روی متغییرهای اتمیک با مد relaxed انجام میشن توی روابط synchronizes-with شرکت نمیکنن. توی روابط happens-befor هم، زمانی شرکت میکنن که توی یک ترد باشن(درواقع منّت سر ما میذارن و sequence-befor رو رعایت میکنن حداقل). بنابراین این عملیاتها تقریبا هیچ الزامی ندارند که بین تردها ترتیب خاصی رو رعایت کنند. تنها الزامی که وجود داره اینه که اگر توی یک ترد مقدار یک متغییر اتمیک خونده شد، دفعات بعدی که توی همون ترد داریم عملیات خوندن داده از همون متغییر اتمیک رو انجام میدیم، به هیچ عنوان نباید امکان اینکه مقادیری که قبل از اولین خوندنمون ذخیره شدن رو بدست بیاریم. یعنی یا همون مقداری که اول خوندیم رو باید بگیریم یا مقادیری که بعد از اولین خوندن ما نوشته شدهاند. در نهایت، تنها چیزی که بین تردها به اشتراک گذاشته میشه فقط modification order هست که باید روش به توافق برسند.
کد زیر یک مثال هست برای اینکه ببینیم این مدل چقدر واقعا ریلکسه!
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true, std::memory_order_relaxed); // 1
y.store(true, std::memory_order_relaxed); // 2
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // 3
if(x.load(std::memory_order_relaxed)) // 4
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0); // Point 5
}اینبار، assert در نقطهٔ شماره ۵ میتونه trigger بشه. یعنی اینکه y میتونه true باشه(نقطه ۳) ولی x مقدار true نداشته باشه(نقطه ۴)، با اینکه در تابع write_x_then_y اول x و سپس y مقداردهی شدن(رابطه happens-befor دارن)! همونطور که گفتیم، توی این مدل هیچ ترتیب خاصی برای عملیاتها(درواقع مشاهدهٔ وضعیت عملیاتها) روی متغییرهای مختلف و در تردهای مختلف وجود نداره.
با اینکه رابطهٔ happens-befor بین خودِ storeها و بین خودِ loadها وجود داره، ولی هیچ رابطهای(نه synchronizes-with نه چیز دیگه) بین یک store و load که توی تردهای مختلف قرار گرفتن وجود نداره. به همین دلیله که loadها میتونن ترتیب متفاوتی از storeها رو ببینن. تصویر زیر رابطهٔ happens-befor کد بالا رو به همراه مقادیر یکی از سناریوها آورده:
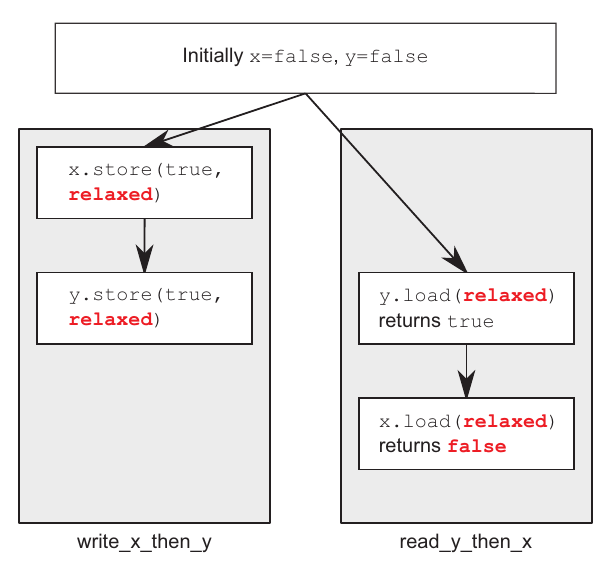
حالا میریم سراغ یه کد که کمی پیچیدهتر باشه:
#include <thread>
#include <atomic>
#include <iostream>
std::atomic<int> x(0),y(0),z(0);
std::atomic<bool> go(false);
unsigned const loop_count=10;
struct read_values
{
int x,y,z;
};
read_values values1[loop_count];
read_values values2[loop_count];
read_values values3[loop_count];
read_values values4[loop_count];
read_values values5[loop_count];
void increment(std::atomic<int>* var_to_inc,read_values* values)
{
while(!go)
std::this_thread::yield();
for(unsigned i = 0; i < loop_count; ++i)
{
values[i].x=x.load(std::memory_order_relaxed);
values[i].y=y.load(std::memory_order_relaxed);
values[i].z=z.load(std::memory_order_relaxed);
var_to_inc->store(i + 1, std::memory_order_relaxed);
std::this_thread::yield();
}
}
void read_vals(read_values* values)
{
while(!go)
std::this_thread::yield();
for(unsigned i=0;i<loop_count;++i)
{
values[i].x=x.load(std::memory_order_relaxed);
values[i].y=y.load(std::memory_order_relaxed);
values[i].z=z.load(std::memory_order_relaxed);
std::this_thread::yield();
}
}
void print(read_values* v)
{
for(unsigned i=0;i<loop_count;++i)
{
if(i)
std::cout<<",";
std::cout<<"("<<v[i].x<<","<<v[i].y<<","<<v[i].z<<")";
}
std::cout<<std::endl;
}
int main()
{
std::thread t1(increment,&x,values1);
std::thread t2(increment,&y,values2);
std::thread t3(increment,&z,values3);
std::thread t4(read_vals,values4);
std::thread t5(read_vals,values5);
go=true;
t5.join();
t4.join();
t3.join();
t2.join();
t1.join();
print(values1);
print(values2);
print(values3);
print(values4);
print(values5);
}توی این برنامه ما ۳ تا متغییر shared global اتمیک داریم. همچنین ۵ تا ترد داریم که مقادیر اون ۳ تا اتمیک رو میخونن و توی آرایههای مربوط به خودشون ذخیره میکنن. ۳ تا از تردها علاوه بر خوندن، مقادیر اتمیکهای گلوبال مورد استفاده رو افزایش میدن. در نهایت بعد از join شدن همهٔ تردها، محتوای آرایههایی که توسط تردها پُر شدن رو چاپ میکنیم. نتیجه همچین چیزی میشه:
(0,0,0),(1,0,0),(2,0,0),(3,0,0),(4,0,0),(5,7,0),(6,7,8),(7,9,8),(8,9,8),(9,9,10)
(0,0,0),(0,1,0),(0,2,0),(1,3,5),(8,4,5),(8,5,5),(8,6,6),(8,7,9),(10,8,9),(10,9,10)
(0,0,0),(0,0,1),(0,0,2),(0,0,3),(0,0,4),(0,0,5),(0,0,6),(0,0,7),(0,0,8),(0,0,9)
(1,3,0),(2,3,0),(2,4,1),(3,6,4),(3,9,5),(5,10,6),(5,10,8),(5,10,10),(9,10,10),(10,10,10)
(0,0,0),(0,0,0),(0,0,0),(6,3,7),(6,5,7),(7,7,7),(7,8,7),(8,8,7),(8,8,9),(8,8,9)۳ تا خط اول مربوط به تردهایی هستند که دارند مقادیر رو مینویسن(به ترتیب، تردی که داره x رو مینویسه، تردی که داره y رو مینویسه و تردی که داره z رو مینویسه.)
همونطور که میبینیم، هرج و مرجی که اینجا برپاست قابل تصور نیست. ترد سوم(اونی که z رو مینویسه) در کل زمان اجراش حتی یکبار هم نتونسته مقادیر x و y که تغییر کردن رو بخونه درحالی که اون دوتا ترد تونستن اینکار رو بکنن. وقتی از relaxed حرف میزنیم، یعنی همچین چیزی.
فهم بهتر relaxed ordering
برای فهم بهتر این مدل، با یک مثال پیش میریم. فرض میکنیم هرکدوم از متغییرها یک کارمند هستند که توی پارتیشن و پشت میز خودشون نشستن و یه دفترچه یادداشت هم دارن. ما میتونیم بهشون زنگ بزنیم و ازشون بخوایم که یه عدد به ما بگن یا اینکه بهشون بگیم یه عدد رو بنویسن. اگر به کارمند بگیم که عدد رو بنویسه، اون عدد رو پایینتر از همهٔ عددهایی که توی لیستش داره مینویسه.
وقتی برای اولین بار از کارمند میخوایم که یک عدد به ما بده، میاد و از بین اعداد توی لیستش هرکدوم که خودش دوست داره رو به ما میده. ولی دفعهٔ بعد که ازش خواستیم به ما عدد بده، دیگه فقط و فقط یا همون عدد قبلی و یا عددهایی که توی لیست پایینتر از عدد قبلیای که به ما داده هستند رو میتونه به ما بده.
اگر بهش بگیم یک عدد رو بنویسه و بعد پشت بندش ازش بخوایم که یک عدد به ما بده، یا همون عددی که ما بهش گفتیم بنویسه رو میده یا عددهایی که بعد از اون توی لیست نوشته شدهن. بنابراین اگر فرض کنیم توی لیست اون کارمند چنین چیزی نوشته شده: 6 10 8 22 45 (به ترتیب از چپ به راست)، دفعه اولی که ازش میخوایم یک عدد رو به ما بده میتونه هرکدوم از این اعداد رو بده. فرض میکنیم عدد ۸ رو میده. حالا اگر دوباره ازش بخوایم که عددی به ما بده، فقط میتونه از بین اعداد ۸ و ۱۰ و ۶ یکیشون رو بده. اگر ۳ بار دیگه ازش بخوایم به ما عدد بده، ممکنه ۲ بار ۸ بده و آخرین بار ۶ بده. اگه بهش بگیم که عدد ۶۶ رو بنویسه، اون رو به انتهای لیستش اضافه میکنه و اگر بعدش ازش بخوایم عدد بده، تا زمانی که عدد دیگهای بعد از ۶۶ اضافه نشده و حال عوض کردن عدد رو هم بدست نیاورده باشه، به ما همون ۶۶ رو میگه.
حالا اگر بجز ما یک فرد دیگه به نام «ممد» هم باشه که به این کارمند زنگ بزنه چی؟ نکته اینکه این کارمند به شکل همزمان فقط با یک نفر میتونه صحبت کنه. حالا فرض کنیم لیست عددهای ما 11 40 29 35 78 باشه. ممد زنگ میزنه و از کارمند یک عدد میخواد و کارمند بهش ۳۵ رو میده. بعدش ما زنگ میزنیم و میگیم عدد ۸۴ رو به لیست اضافه کنه. دفعه بعد که ممد زنگ بزنه و عدد بخواد، کارمند کدوم یکی از اعداد رو بهش میده؟ همچنان میتونه همهٔ اعداد از ۳۵ تا ۸۴ رو بهش بده. الزامی نداره که حتما ۸۴ رو بده. همچنین برعکس، صرفا بخاطر اینکه ممد یک عددی رو بهش گفته باعث نمیشه که کارمند مجبور بشه همون عدد و اعداد بعدش رو به ما بده. بنابراین این کارمند به طریقی برای خودش نگه میداره که جای هرکسی توی این لیست کجاست و موقعی که میخواد عددی رو به شخص x بده، بین اعداد موجود در جایگاه x تا انتهای لیست میگرده و یکی رو انتخاب میکنه و به اعداد قبل از جایگاه x کاری نداره.
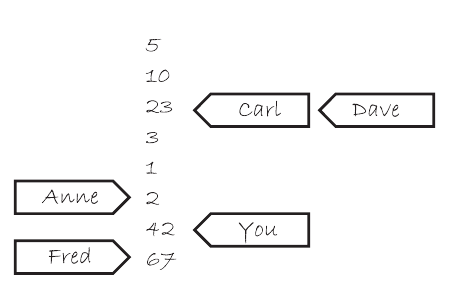
حالا تصور کنید که یک کارمند که پشت میزش/توی پارتیشنش نشسته نداریم. یک طبقه کامل پر از کارمندها داریم که هرکدوم تلفن و دفترچه یادداشت خودشون رو دارند. این کارمندها همون متغییرهای اتمیک ما هستند و دفترچه یادداشتها درواقع همون modification order هستند و هیچ ارتباطی بین این کارمندها نیست. ماهایی که زنگ میزنیم(من، شما، ممد و ...) میشیم تردها. این میشه توصیف سادهای از وضعیتی که عملیاتهای دارای memory_order_relaxed دارند.
مثالی که بالاتر کدش رو نوشتیم رو دقیقا میشه با همین داستانی که تعریف کردیم انطباق داد. ما به دو کارمند (x و y) زنگ میزنیم و میگیم که مقدار true رو توی لیستشون بنویسن. بعدش انقدر به کارمند y زنگ میزنیم تا به ما مقدار true رو بده. سپس به کارمند x زنگ میزنیم و میگیم یه مقداری رو به ما بده. اون x هیچ تعهدی نداره که به ما مقدار true رو بده و هرکار دلش بخواد انجام میده :)
به دلیل ذاتی که این نوع مدل حافظه داره، برای اینکه بتونیم ازش بهره ببریم باید ترکیبی از این مدل رو با مدلهای دیگه که دارای ترتیب خاصی هستند استفاده کنیم.
یکی از اون مدلها، acquire-release هست که نه سربار seq cst رو داره نه رهایی relaxed.
Acquire-Release Ordering
مدل acquire-release یک قدم رو به پیشرو نسبت به مدل relaxed محسوب میشه. در این مدل همچنان هیچ ترتیب کلیای وجود نداره و تنها یکسری همگامسازیها به صورت اضافه هست. در این مدل، عملیات load اتمیک از نوع acquire و عملیات store اتمیک از نوع release هستند و عملیات read-modify-write میتونن هم از نوع acquire، هم از نوع release و هم جفتشون(memory_order_acq_rel) باشند. همگامسازی به شکل جفتی انجام میگیره. یعنی اینکه یک عملیات release روی یک متغییر اتمیک، با یک عملیات acquire روی همون متغییر اتمیک(که مقدار نوشته شده رو میخونه) رابطه synchronizes-with برقرار میکنه. این به این معنیه که همچنان تردهای مختلف میتونن ترتیبهای مختلفی رو ببینن. با این تفاوت که این ترتیبهای مختلف نسبت به مدل relaxed تعداد کمتری دارن. مثال مربوط به sequential consistency رو با استفاده از acquire-release بازنویسی میکنیم:
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x()
{
x.store(true, std::memory_order_release);
}
void write_y()
{
y.store(true, std::memory_order_release);
}
void read_x_then_y()
{
while(!x.load(std::memory_order_acquire));
if(y.load(std::memory_order_acquire)) // Point 1
++z;
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire));
if(x.load(std::memory_order_acquire)) // Point 2
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0); // Point 3
}توی این کد هم assert میتونه trigger بشه :) بخاطر اینکه امکانش هست مقدار load شدهٔ از متغییر x(نقطهٔ ۲) و متغییر y(نقطهٔ ۱) برابر با false باشند. نوشتن x و y توی دو ترد مختلف انجام شده بنابراین این ترتیبی که از رابطهٔ بین acquire و release وجود داره تاثیری روی کار تردهای دیگه نداره. این جملهای که نوشتم و رابطهٔ happens-befor بین تردها رو میشه با عکس پایین بهتر متوجه شد و ببینیم چطور هر ترد دید خودش از دنیای اطرافش رو داره:
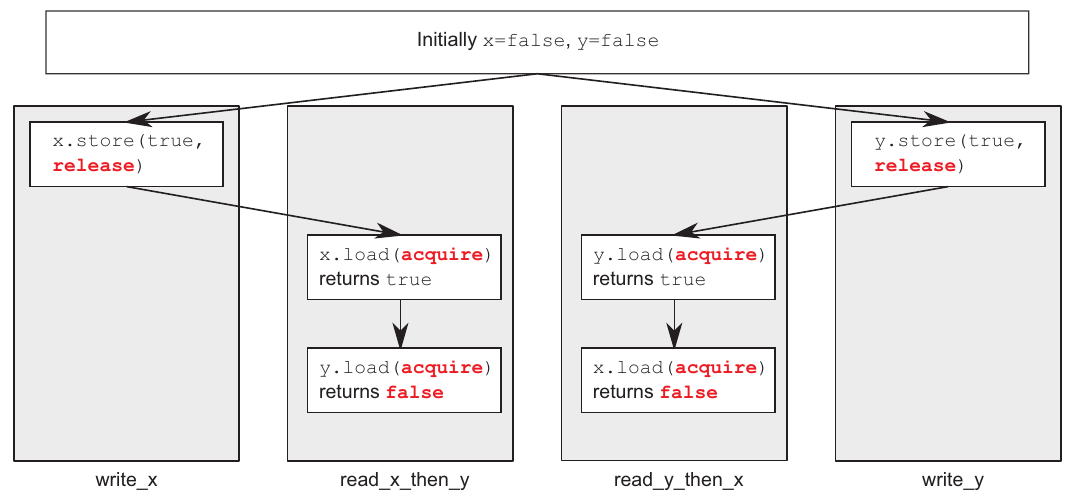
برای اینکه از قابلیت همگامسازی بین release و acquire بتونیم استفاده کنیم، باید هردوتا store خودمون رو توی یک ترد بذاریم. اینطوری میتونیم ترتیب مدنظر خودمون رو به برنامه تحمیل کنیم. کد پایین:
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // Point 1
y.store(true,std::memory_order_release); // Point 2
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire)); // Point 3
if(x.load(std::memory_order_relaxed)) // Point 4
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0); // Point 5
}توی این کد دیگه assert نمیتونه fire بشه :) چطوری؟ عملیات store روی y(نقطهٔ ۲) که یک memory_order_release تعیین شده، با عملیات load روی y(نقطهٔ ۳) که مدل memory_order_acquire رو همراه خودش داره رابطهٔ synchronizes-with برقرار میکنه. همچنین رابطهٔ happens-befor بین store روی y و load روی y برقرار میشه. حالا از اونجایی که store روی x توی همون تردی انجام شده که store روی y هست، این دوتا میتونن ترتیب داشته باشند. یعنی میدونیم که store روی x با store روی y رابطهٔ happens-befor داره(یعنی قبل از store y اتفاق میوفته). همچنین load کردن y(نقطهٔ ۳) و load کردن x (نقطهٔٔ ۴) هم باهمدیگه رابطهٔ happens-befor دارند(چون توی یک ترد هستند و sequence-befor برقراره).
خلاصهش:
- عملیات store روی x قبل از store روی y اتفاق میوفته(store x happens befor store y)
- عملیات store روی y با load روی y همگام میشه. پس میشه نتیجه گرفت وقتی y == true هست، یعنی store روی y قبل از load روی y اتفاق افتاده(store y happens befor load y)
- عملیات load روی y قبل از load روی x اتفاق میوفته(load y happens befor load x)
از اونجایی که store y قبل از load y و همچنین load y قبل از load x اتفاق میوفته، میشه از طریق رابطهٔ تعدی نتیجه گرفت که store y قبل از load x اتفاق میوفته. حالا این رو که گسترش بدیم میتونیم نتیجه بگیریم که store x قبل از load x اتفاق افتاده :)
به این صورت ما ترتیب خودمون رو ایجاد کردیم.
یک نکته اینکه برای ایجاد شدن رابطهٔ synchronizes-with باید حتما acquire و release باهمدیگه جفت بشن و این زمانی اتفاق میوفته که مقدار نوشته شده توسط store، برای load قابل مشاهده باشه. بنابراین اگر در نقطهٔ ۳ ما حلقه while رو نداشتیم دیگه روابط بالا برقرار نمیبودن چون ممکن بود که load y مقدار false برگردونه.
اگر بخوایم مثال کارمند و تلفن و یادداشت رو برای این مدل پیادهسازی کنیم، باید چندتا چیز به مثالمون اضافه کنیم. اول اینکه هر storeای که انجام میشه، عضو یک دسته(batch) خواهد بود. بنابراین زمانی که زنگ میزنیم تا بگیم عددی رو بنویسه، باید بگیم که توی کدوم دسته باید بنویسه. و اگر آخرین عددی بود که ما میخواستیم توی اون دسته نوشته بشه، این رو هم باید بگیم. بنابراین برای اضافه کردن عدد مثلا چنین چیزی میگیم: «عدد ۲ رو توی دستهٔ شماره ۵۵ از طرف ممد بنویس». اگر عددی که میخوایم بنویسیم آخرین عددی باشه که قراره نوشته بشه، این رو به کارمند میگیم: «عدد ۲ رو توی دستهٔ شماره ۵۵ بنویس و این آخرین عددی هست که توی این دسته بهت میگم». این همون store یا release توی اتمیک هست.
وقتی هم که باهاش تماس میگیریم و میخوایم ازش عددی رو درخواست کنیم، به دو صورت اینکار رو میکنیم:
- بهش میگیم «لطفا یک عدد از دستهٔ شماره ۲ به من بده». این میشه همون memory_order_relaxed
- یا اینکه میتونیم بهش بگیم «لطفا یک عدد از دستهٔ شماره ۲ به من بده و بگو که آیا این آخرین عضو اون دسته هست یا نه». این میشه acquire
اگر عددی که به ما برمیگردونه آخرین عضو دستهٔ خودش باشه، این رو به ما اطلاع میده که آخرین عضو رو داره به ما میده.
حالا کد بالا رو با استفاده از این مثال بررسی میکنیم.
- ترد a درحال اجرای write_x_then_y هست. بنابراین به کارمند x زنگ میزنه و میگه که «مقدار true رو از طرف ترد a به عنوان عضوی از دستهٔ شماره ۱ یادداشت کن». کارمند اینکار رو انجام میده.
- حالا ترد a به کارمند y زنگ میزنه و میگه که «مقدار true رو از طرف ترد a به عنوان آخرین عضو دستهٔ ۱ یادداشت کن». کارمند اینکار رو انجام میده.
- همزمان که دو مورد بالا دارند اتفاق میوفتند،ترد b داره read_y_then_x رو انجام میده که طی اون همش با کارمند y تماس میگیره و ازش میخواد که «یک مقدار به همراه اطلاعات دستهاش رو بده». انقدر اینکار رو تکرار میکنه تا کارمند y بهش مقدار true بده. کارمند y علاوه بر مقدار، به ترد b میگه که «این مقدار، آخرین عضو دستهٔ شماره ۱ از طرف ترد a بوده».
- حالا ترد b به کارمند x تلفن میزنه و میگه که «من یک مقدار میخوام و البته من دربارهٔ یک دسته به شماره ۱ که از طرف ترد a هست هم اطلاع دارم. بگرد ببین همچین چیزی داری یا نه». کارمند x توی لیستش نگاه میکنه تا آخرین جایی که حرف از دستهٔ ۱ از طرف ترد a شده کجاست. و میبینه که مقدار true آخرین و تنها مقداری هست که توی لیست خودش داره. بنابراین باید مقدار true رو برگردونه :)
جمع بندی
والا چی بگم! یه نگاه تقریبا کلی به انواع memory orderها انداختیم و فهمیدیم sequentially consistent خیلی راحت کار مارو انجام میده ولی هزینهش زیاده، acquire-release چیز خوبیه ولی نیاز به دقت داره و راجع به relaxed هم که بهتره تا جایی که میشه ازش استفاده نکنیم چون پیچیدگی کد رو بالا میبره.
پست بعدی درباره استفاده از رابطهٔ تعدیِ رابطهٔ happens-befor توی مدل acquire-realase خواهد بود.