مباحث پیچیدهتر در memory ordering
حالا که مباحث ابتدایی ترتیبهای حافظه (memory ordering) رو باهم دیدیم، وقت اینه که یکم مسائل پیچیدهتری رو بررسی کنیم.


حالا که مباحث ابتدایی ترتیبهای حافظه (memory ordering) رو باهم دیدیم، وقت اینه که یکم مسائل پیچیدهتری رو بررسی کنیم. اولیش، Release Sequenceها هستن.
Release Sequenceها
یکم این مفهوم برام گُنگ بود. کتاب میتونست مثالهای بیشتری بزنه و مسئله رو بیشتر باز کنه چون رسما یجورایی برخی از قوانین قبلی رو نقض میکنه.
دیدیم که در صورت استفاده از برچسبهای مناسب، بین یک store روی یک متغییر اتمیک و load روی همون اتمیک، رابطهٔ synchronizes-with برقرار میشه، حتی اگر بین اون store و load مورد نظر، توالیای از عملیاتهای read-modify-write وجود داشته باشه. حالا اینجا چیزی که قبلا گفتیم رو یکم بسط میدیم.
اگر storeای که گفتیم یکی از برچسبهای memory_order_release، memory_order_acq_rel یا memory_order_seq_cst رو داشته باشه و عملیات load هم یکی از برچسبهای memory_order_acquire، memory_order_consume یا memory_order_seq_cst رو داشته باشه و اگر هر کدوم از عملیاتهای دیگهای که توی زنجیرهٔ بین این دو عملیات قرار دارند، مقدار نوشته شده قبل از خودشون رو load کنند، یک Release Sequence تشکیل میشه که در طی این توالی، اولین store با آخرین load رابطهٔ synchronizes-with برقرار میکنه(البته در صورتی که از memory_order_consume استفاده بشه، بجای رابطهٔ synchronizes-with رابطهٔ dependency-ordered-befor رو خواهیم داشت).
توی زنجیرهٔ عملیاتها، هر عملیات read-modify-write میتونه هر برچسبی که دلش میخواد(حتی memory_order_relaxed) رو داشته باشه!
مثالی که کتاب آورده رو باهمدیگه بررسی میکنیم تا بهتر بفهمیم مفهوم این موضوع چی هست.
#include <atomic>
#include <thread>
std::vector<int> queue_data;
std::atomic<int> count;
void populate_queue()
{
unsigned const number_of_items=20;
queue_data.clear();
for(unsigned i=0;i<number_of_items;++i)
{
queue_data.push_back(i);
}
count.store(number_of_items,std::memory_order_release); // Point 1 -> The initial store
}
void consume_queue_items()
{
while(true)
{
int item_index;
if((item_index=count.fetch_sub(1,std::memory_order_acquire))<=0) // Point 2
{
wait_for_more_items(); // Point 3
continue;
}
process(queue_data[item_index-1]); // Point 4
}
}
int main()
{
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread c(consume_queue_items);
a.join();
b.join();
c.join();
return 0;
}یک ترد تولیدکنندهٔ داده و دو ترد استفادهکنندهٔ داده داریم که این دادهها در یک صفِ مشترک خونده/نوشته میشن. با استفاده از یک متغییر atomic<int> تعداد عناصر موجود در صف رو نگهمیداریم. در این کد ما اینکار رو به این شکل انجام دادیم که ترد تولیدکننده اول دادهها رو ایجاد میکنه و در صف قرار میده سپس با استفاده از یک عملیات store، به بقیه تردها خبر میده که داده آماده شده(نقطهٔ ۱). تردهای استفاده کنندهٔ داده با استفاده از یک عملیات sub_fetch که برچسب memory_order_acquire داره، شمارهٔ عنصری که میخوان از صف بخونن رو برمیدارن و سپس از داخل صف/بافر اون رو میخونن(نقطهٔ ۴). طبیعیه که وقتی مقدار count برابر با صفر شد یعنی دیگه دادهای وجود نداره و تردها صبر میکنن(نقطهٔ ۳). تا اینجاش به نظر بدیهی میاد نه؟
بله در صورتی کاملا بدیهی هست که یک ترد استفادهکننده داشته باشیم؛ چراکه با استفاده از memory_order_acquire به راحتی با store اولیه همگام میشه و مشکلی نیست. اما اینجا دوتا ترد استفادهکننده داریم که ترد دوم درواقع داره نتیجهای که توسط fetch_sub ترد اول نوشته شده رو میخونه. جفت تردهای استفادهکنندهٔ ما برچسب memory_order_acquire رو داشتند پس فرآیند sync شدنشون چطور اتفاق میوفته؟ با استفاده از قانون Release Sequence :)
بدون قانون Release Sequence، دومین ترد دیگه رابطهٔ happens-befor با اولین ترد برقرار نمیکرد و در نتیجه عملیات خوندن از بافر مشترک دیگه safe نبود مگر اینکه تردهای استفادهکننده، برچسب memory_order_release رو هم مورد استفاده قرار میدادن تا بینشون رابطهٔ happens-befor برقرار باشه که اینکار درواقع باعث میشه الکی سرباز synchronization بین دوتا تردِ مصرفکننده بوجود بیاد. همچنین، بدون وجود قانون Release Sequence یا استفاده از memory_order_release توی fetch_subها، تضمینی نبود که ذخیرهٔ دادهها توی صف مشترک برای ترد مصرفکنندهٔ دوم قابل مشاهده باشه و در نتیجه اینجا Data Race میداشتیم.
اما حالا که اولین fetch_sub از قانون Release Sequence پیروی میکنه، عملیات store با fetch_sub دومی هم sync میشه و همچنین هیچ synchronizes-withای بین دوتا ترد مصرفکننده نداریم.
تصویر پایین، یک خلاصهای از توضیحات بالا رو نشون میده(که همونطور که گفتم به نظرم به نسبت اهمیتش، خیلی کوتاه توی کتاب توضیح داده شده و به شخصه برای من کلی نکتهٔ گُنگ ایجاد کرده). خطوط نقطهای نشوندهندهٔ Release Sequence و خط پررنگ نشوندهنده رابطهٔ happens-befor هست.
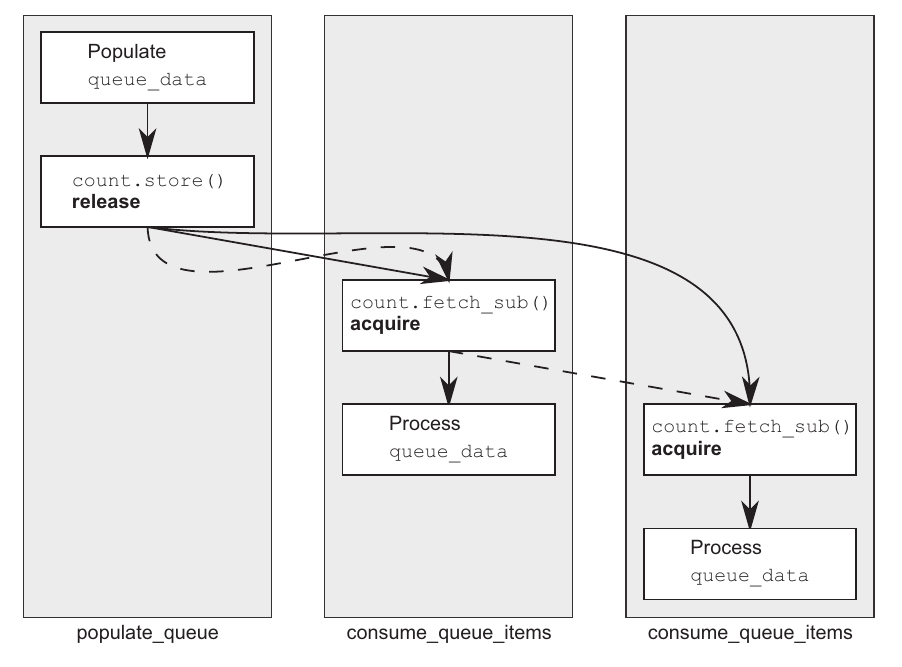
طبق گفتهٔ کتاب، هر چندتا پیوند دیگه میتونه توی این زنجیره حضور داشته باشه و مادامی که از نوع عملیاتهای read-modify-write و دارای برچسب memory_order_acquire باشه، عملیات store با هرکدومشون sync میشه.
فنسها(Fences)
کتابخونهٔ عملیاتهای اتمیک بدون وجود فنسها کامل نخواهد بود. فنسها درواقع عملیاتهایی هستند که محدودیتهای ترتیب حافظهای رو بدون اینکه دادهای رو modify کنن اعمال میکنن. همچنین، فنسها معمولا در ترکیب با عملیاتهایی که برچسب memory_order_relaxed دارند استفاده میشوند. فنسها Global Operationهایی هستند که روی ترتیب دیگر عملیاتهای اتمیک در تردی که فنس در اون اجرا شده اثر میذارن. به فنسها عموما Memory Barrier هم میگن که این اسم به این خاطر بهشون اطلاق میشه که درواقع میان یک مانع/خط در جایی از کد ایجاد میکنن که یکسری عملیاتهای خاص نتونن از اون مانع/خط رد بشن.
همونطور که قبلا خوندیم عملیاتهای با برچسب memory_order_relaxed روی اتمیکهای متفاوت، میتونستن آزادانه توسط کامپایلر یا سختافزار جابجا بشن؛ میتونیم با فنسها کاری بکنیم که آزادیِ این عملیاتها کمتر بشه و براشون روابط happens-befor و synchronizes-with رو هم تعریف بکنیم. کدی که قبلا برای مثال memory_order_relaxed نوشته بودیم رو اینبار با استفاده از فنسها بازنویسی میکنیم:
#include <atomic>
#include <thread>
#include <assert.h>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // Point 1
std::atomic_thread_fence(std::memory_order_release); // Point 2
y.store(true,std::memory_order_relaxed); // Point 3
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // Point 4
std::atomic_thread_fence(std::memory_order_acquire); // Point 5
if(x.load(std::memory_order_relaxed)) // Point 6
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0); // Point 7
}زمانی که عملیات load y(نقطهٔ ۴) مقداری که توسط store y (نقطهٔ ۳) نوشته شده باشه رو بخونه، فنس Release با فنس Acquire رابطه synchronizes-with برقرار میکنه و در نتیجه، عملیات store x (نقطهٔ ۱) با عملیات load x (نقطهٔ ۶) رابطهٔ happens-befor برقرار میکنه بنابراین assert هیچوقت trigger نمیشه :)
توی مثالی که قبلا راجع به memory_order_relaxed زده بودیم دیدیم که در شرایط مشابه(بدون فنس) امکان trigger شدن assert کاملا وجود داشت و عملا ترتیبی برای اجرا شدن عملیاتهای مربوطه وجود نداشت.
توی مثال بالا، استفاده از فنس Release درواقع مثل این میمونه که عملیات store y رو با برچسب memory_order_release و عملیات load y رو با برچسب memory_order_acquire اجرا بکنیم و در واقع ایدهٔ پشت فنسها همینه:
اگر یک عملیات acquire بتونه مقداری که توسط یک عملیات storeای که بعد از یک فنس release اومده رو ببینه، اون فنس با اون عملیات acquire خاص رابطهٔ synchronizes-with برقرار میکنه.
اگر یک عملیات load ای که قبل از یک فنس acquire اومده بتونه مقداری که توسط یک عملیات store با برچسب release رو ببینه، اونوقت اون عملیات store با فنس acquire رابطهٔ synchronizes-with برقرار میکنن.
و اگر مثل کد بالا در هر دو سمت فنس داشته باشیم و عملیات load قبل از فنس acquire و عملیات store بعد از فنس release قرار داشته باشن و اون عملیات load بتونه مقداری که توسط store نوشته شده رو بخونه، بین فنس release و فنس acquire یک رابطهٔ synchronizes-with برقرار میشه.
نکتهٔ مهم اینکه، درسته که sync شدن فنسها با خونده شدن مقداری که store شده اتفاق میوفته اما باید یادمون باشه که نقطهای که sync اتفاق میوفته، در محل وجود فنسها هست.
نقطهای که sync اتفاق میوفته، در محل وجود فنسها هست.
بنابراین اگر توی مثال بالا، store x رو بعد از فنس release بذاریم دیگه تضمینی برای trigger نشدن assert نیست.
درواقع شاید بشه اینطور در نظر گرفت که تا قبل از خونده شدن مقدارِ نوشتهشده در y، فنس/مانع/خط ما جلوی وقوع store x رو گرفته و وقتی که مقدارِ نوشتهشده در y به شکل صحیح خونده میشه، اون مانع برداشته میشه عملیات store x انجام میگیره.(یعنی ما مطمئنیم که انجام گرفته).
مدیریت ترتیب عملیاتهای غیر اتمیک با استفاده از متغییرهای اتمیک
اگه در مثالی که برای فنس نوشتیم، جای x رو با یک متغییر غیر اتمیک عوض کنیم چه اتفاقی میوفته؟
#include <atomic>
#include <thread>
#include <assert.h>
bool x = false;
std::atomic<bool> y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // Point 1
std::atomic_thread_fence(std::memory_order_release); // Point 2
y.store(true,std::memory_order_relaxed); // Point 3
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // Point 4
std::atomic_thread_fence(std::memory_order_acquire); // Point 5
if(x.load(std::memory_order_relaxed)) // Point 6
++z;
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load() != 0); // Point 7
}نتیجهای که اتفاق میوفته چی هست؟ دقیقا مطابق نتیجهٔ قبلی! فنسها همچنان ترتیب مورد نظر ما رو enforce میکنن و عملیات store x قبل از store y و این خودش قبل از load y و این هم خودش قبل از load x اتفاق میافتند. به عبارت دیگه، روابط happens-befor و synchronizes-with به قوت خود باقی هستند و این کار با استفاده از متغییر اتمیک y و فنسها انجام شده. البته فقط فنسها نیستند که میتونن اینکار رو بکنن. مثلا قبلا دیدیم که memory_order_release و memory_order_consume توی همگام کردن متغییرهای غیر اتمیک چطور کار میکنن.
مدیریت ترتیب عملیاتهای غیر اتمیک
برای ترتیبدهی به عملیاتهای غیر اتمیک از طریق عملیاتهای اتمیک، رابطهٔ sequenced-befor خیلی اهمیت پیدا میکنه. اگر یک عملیات غیر اتمیک رابطهٔ sequenced-befor با یک عملیات اتمیک داشته باشه و اون عملیات اتمیک با یک عملیاتِ اتمیکِ دیگه توی یک ترد دیگه رابطهٔ happens-befor داشته باشه، اونوقت عملیاتِ غیر اتمیکی که گفتیم هم رابطهٔ happens-befor با عملیاتِ اتمیکِ دوم برقرار میکنه.
این موضوع درواقع پایه و اساس قابلیتهای همگامسازی سطح بالا (high level)ای مثل Mutex و Condition Variable هست. کتاب، یک SpinLock رو برای مثال پیادهسازی کرده ولی برای من یک سوالی مطرح هست که نتونستم جوابش رو پیدا کنم. اگر کسی این پُست رو خوند و جوابش رو میدونست ممنون میشم کامنت بذاره :)
مثال:
class spinlock_mutex
{
private:
std::atomic_flag flag;
public:
spinlock_mutex() : flag(ATOMIC_FLAG_INIT) {}
void lock()
{
while(flag.test_and_set(std::memory_order_acquire));
}
void unlock()
{
flag.clear(std::memory_order_release);
}
};همونطور که میبینیم، عملیات lock توی مثال بالا درواقع یک test_and_set() با برچسب memory_order_acquire هست. flag در زمان شروع به حالت clear درمیاد بنابراین زمانی که اولین ترد سعی میکنه عملیات lock رو انجام بده، flag به حالت set انتقال پیدا میکنه و این نشانگر این هست که قفل انجام شده. حالا اون تردی که lock رو انجام داده میتونه هر دادهای که توسط این mutex ما تحت حفاظت قرار گرفته رو modify کنه و کلا هر بلایی دلش میخواد سرش بیاره. توی این بین، تردهای دیگه که دارن سعی میکنن lock رو انجام بدن، توی حلقهٔ test_and_set میمونن تا زمانی که flag به حالت clear دربیاد.
عملیات unlock با استفاده از flag.clear() که برچسب memory_order_release داره انجام میشه. به این ترتیب، عملیات clear کردن با عملیات test_and_set که برچسب memory_order_acquire داره (و تردهای دیگه دارن برای قفل کردن mutex ازش استفاده میکنن)، همگام میشه. همچنین، از اونجایی که همهٔ modificationها روی دادههای حفاظتشده، دارای رابطهٔ sequenced-befor با عملیات unlock هستند، پس ناگزیر هستند که رابطهٔ happens-befor با unlock داشته باشن و از اونجایی که unlock، با lockای که تردهای دیگه دارن سعی میکنن انجامش بدن رابطهٔ happens-befor داره، پس در نهایت دادهای که تردهای دیگه بعد از قفل کردن mutex میبینن یک دادهٔ بهروز و همگام شدهست.
یک Mutex رو میشه به شکلهای مختلف پیادهسازی کرد اما تقریبا ایدهٔ همهشون یجوره: عملیات lock یک عملیات acquire و عملیات unlock یک عملیات release هست.
سوال
همونطور که بالاتر گفتم، یک چیزی برای من در پیادهسازی SpinLock یاد شده کمی گُنگ هست و اون هم ارتباط بین test_and_setهای مختلف هست.
درواقع سوال این هست که زمانی که برای اولین بار عملیات lock با test_and_set انجام میشه، هیچ releaseای وجود نداره که بخوایم release-sequence داشته باشیم. پس چطور ترد دومی که داره سعی میکنه test_and_set انجام بده متوجه میشه که flag مربوطه set شده؟ چون عملیات test_and_set ما برچسب acquire داره بنابراین اینا نمیتونن باهمدیگه همگام بشن.
مخصوصا بابت این پاراگراف کتاب که کاملا من رو سردرگم کرد:
with memory_order_acquire semantics doesn’t synchronize with anything, even though
it stores a value, because it isn’t a release operation. Likewise, a store can’t synchronize
with a fetch_or with memory_order_release semantics, because the read part of the
fetch_or isn’t an acquire operation.
اما بعدتر توی استاندارد این رو دیدم:
با خوندن این اولش دیگه واقعا سردرگم بودم(الآنم هنوز کمی هستم) ولی بعدش فکر کردم و گفتم احتمالا منظور کتاب از اینکه «توی انتخاب برچسب یک عملیات read-modify-write باید دقت کنیم چون ممکنه sync نشن»، از جهت ارتباطش با عملیاتهایی غیر از read-modify-write بوده. اگر این فرض رو داشته باشم اونوقت کد SpinLock منطقی به نظر میرسه.
اما خب بهرحال مطمئن نیستم از این پاسخ.
پایان
خب این فصل هم تموم شد. خیلی فصل سختی بود به نظرم! پُر از مفاهیم انتزاعی که درک کردنشون برای منی که خیلی سخت تمرکز میکنم و همون تمرکز کم رو هم نمیتونم زیاد نگهدارم، مشکل بود.
فصل بعدی دربارهٔ طراحی و پیادهسازی ساختماندادههای Lock Based هست.